Twitter Sentiment Analysis in Java
Sentiment analysis is an application of Natural Language Processing (a branch of Artificial Intelligence) that revolves around detecting the sentiment of text. A common dimension for measuring sentiment uses labels positive, negative and neutral, as well as many other possibilities (i.e. how strong the sentiment is, how active vs subdued it is, etc). This thesis illuminates the perennial conundrum of predicting sentiment from short pieces of text, predominantly engendered in social networking sites. The challenge becomes an overriding concern if the resulting use of the language that does not conform entirely to grammatical and syntactical rules and the constraints that the short text imposes are taken into careful consideration. The Word-Graph Sentiment Analysis Method is proposed to identify the sentiment of the tweets via the containing sequence of the words. In fact, the value of the application counterweights the endeavor difficulty allowing the social media users to quickly and automatically evaluate the public’s disposition towards multiple topics. As such, in recent years sentiment analysis has manifested itself as an indispensable methodology in marketing and other suchlike application domains.
The proposed approach for sentiment analysis is concerned with a novel method for modeling the tweets, called Word-Graph Sentiment Analysis Method. This approach combines the graph structure with graph similarity metrics and classification methodologies in order to automatically infer the sentiment expressed by the author of the tweet towards a pre-selected topic. In this project, the words contained in a short tweet are represented as vertices and the vicinity between the words as edges. Figure 1 contains two sample tweets about the current series Falcon and the Winter Soldier, one positive and one negative. As companies aspire to obtain detailed insights into the way their products are being perceived, social media is a particularly popular arena for deploying sentiment analysis. As a result, there are many organisations offering apps or services for building them; a screenshot from a demo of such an app is given in Figure 2.
 source: marketmotive.com
source: marketmotive.com
The earliest and simplest techniques for performing sentiment analysis (although this type of approach is still in fact widely used) only conducted keyword matching in the text on the basis of words from a sentiment lexicon (i.e. a source of words that have known sentiment). Often, these lexicons do not have extensive coverage: there are many words with sentiment that are not included in them, particularly in the case of social media text, where misspellings, abbreviations and slang are common. Consequently, there are other approaches to the task: there’s a large class of machine learning techniques applied, as well as other techniques like label propagation, where sentiment labels are propagated through a graph structure.
In this project, I have worked with a set of real tweets collected by researchers who developed one of the first approaches to sentiment analysis of tweets, and constructed my own tweet sentiment analyser . Early stages of the project only employ a keyword-based approach, building up to a simple version of label propagation later.

There are four sorts of data required.
-
Tweets: Early sentiment analysis work included the collection of a set of tweets, some for training a machine learning model for sentiment analysis, and some for evaluating how good that model was. The same data were utilised in this project with the following information for each tweet:
• the gold polarity of the tweet (0 = negative, 2 = neutral, 4 = positive, = not given) • the id of the tweet (2087) • the date of the tweet (Sat May 16 23:58:44 UTC 2009) • the query (lyx) • the user that tweeted (e.g. robotickilldozr) • the text of the tweet (e.g. Lyx is cool)

- Basic Sentiment Words: There is a widely used subjectivity and sentiment lexicon from which the data were extracted. Each line is comprised of a word, followed by the typical sentiment of that word without any additional context, indicated by the string positive or negative, e.g.
- Finegrained Sentiment Words: The full lexicon from above also includes information about the strength of the sentiment: weaksubj indicates weak sentiment, and strongsubj strong.

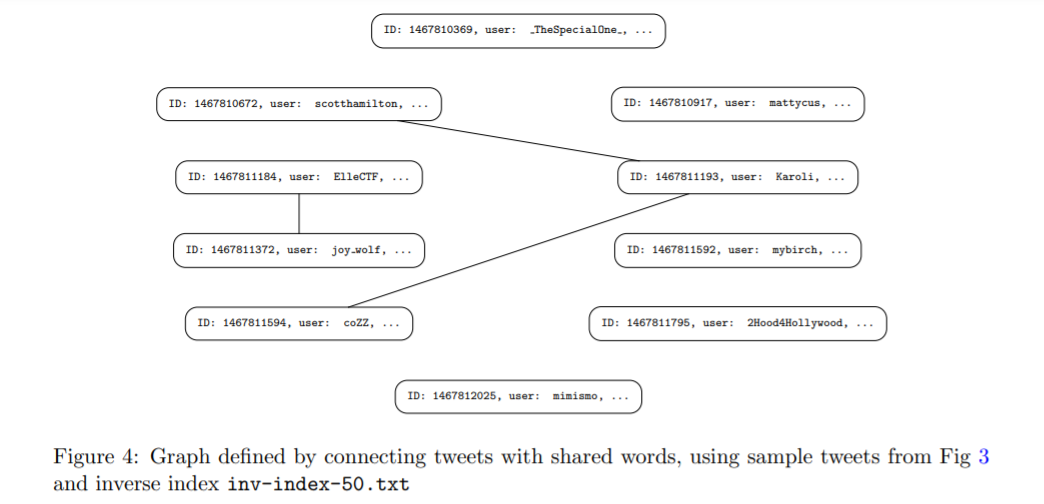
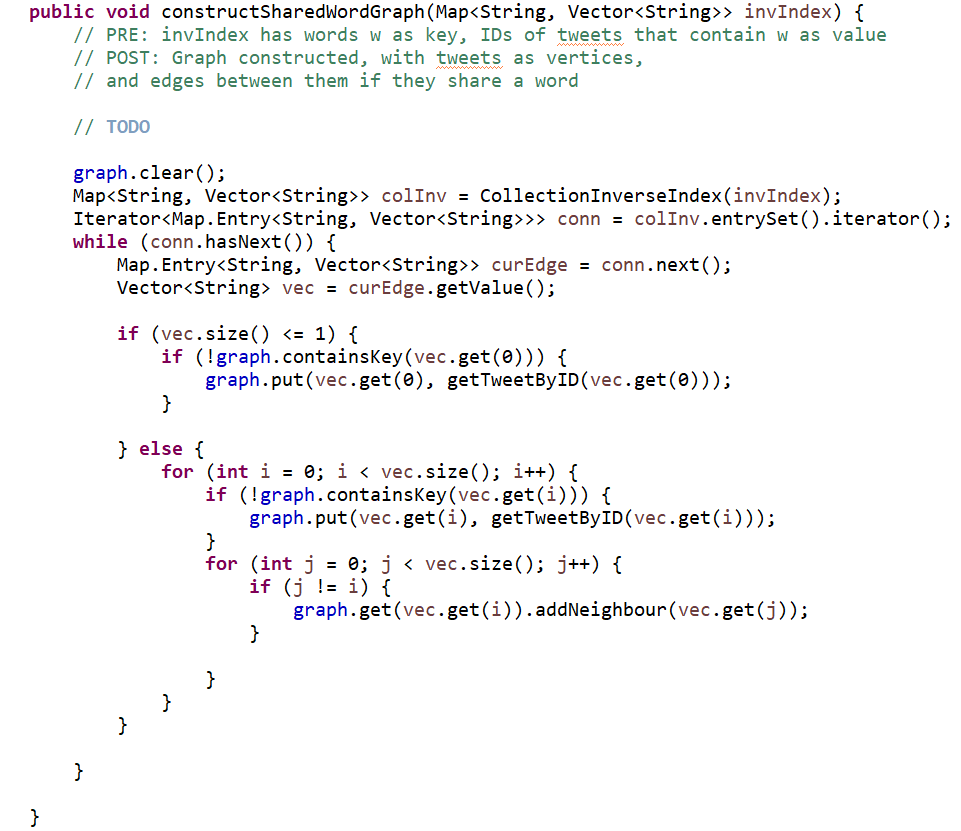
- Inverse Index: This requires constructing a graph, linking tweets that share words.

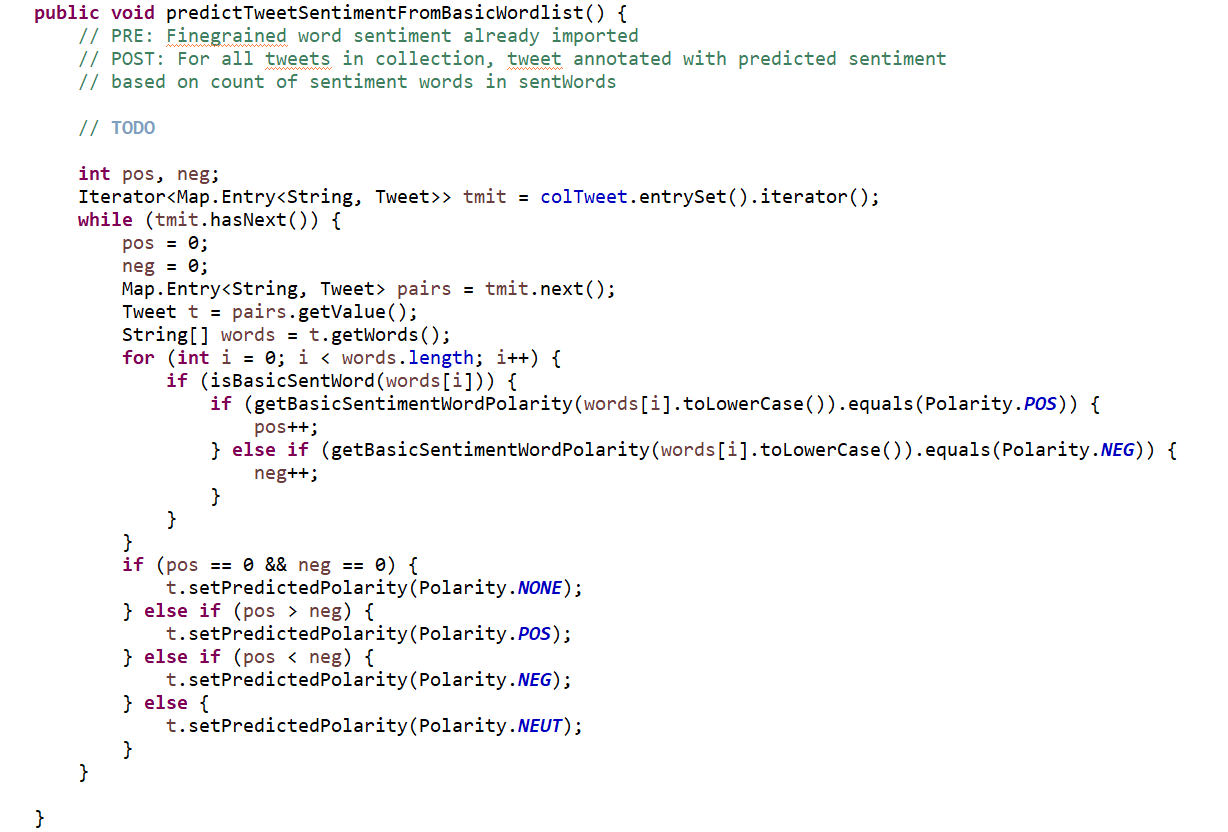
Two classes, Tweet and TweetCollection, were created. While the former represents an individual tweet, the latter represents a collection of them. A simple keyword-based method was then implemented for sentiment analysis of tweets, computing the total of positive and negative words in a tweet to determine the predicted polarity of the tweet.
In the approach to sentiment labelling, I ended up with quite a few unlabelled tweets, because several of them did not contain words from the sentiment lexicon. As noted earlier, another technique is to propagate sentiment labels from one tweet to another (similar) one. Therefore, a graph that linked together ‘similar’ tweets (for some definition of similarity) was constructed, and then connected components in the graph were identified with a view to propagating sentiment labels via the edges in the graph within those connected components.
The ultimate goal after constructing the graph is to propagate sentiment labels via the edges in the graph defined, and the majority labels in those connected components. Additionally, a richer sentiment labelling scheme was employed thereafter.
To reiterate, the Word-Graph Sentiment Analysis Method was applied for the identification of the tweet sentiment using the sequence of the words that contained. The sequence of the words can be represented using graphs in which the application of graph similarity metrics and classification algorithms can help facilitate sentiment predictions. Experiments that were undertaken with this method in a Twitter dataset validate the proposed model, enabling us to further understand the metrics and the criteria that can be applied in words-graphs for the Twitter sentiment prediction.